
Data cleaning with Kamehamehas in R
Background
Given present circumstances in in the world, I thought it might be nice to write a post on a lighter subject.
Recently, I came across an interesting Kaggle dataset that features the power levels of Dragon Ball characters at different points in the franchise. Whilst the dataset itself is quite simple with only four columns (Character, Power_Level, Saga_or_Movie, Dragon_Ball_Series), I noticed that you do need to do a fair amount of data and string manipulation before you can perform any meaningful data analysis with it. Therefore, if you’re a fan of Dragon Ball and interested in learning about string manipulation in R, this post is definitely for you!

The Kamehameha - image from Giphy
For those who aren’t as interested in Dragon Ball but still interested in general R tricks, please do read ahead anyway - you won’t need to understand the references to know what’s going on with the code. But you have been warned for spoilers! 😂
Functions or techniques that are covered in this post:
- Basic regular expression (regex) matching
stringr::str_detect()stringr::str_remove_all()orstringr::str_remove()dplyr::anti_join()- Example of ‘dark mode’ ggplot in themes
Getting started
You can download the dataset from Kaggle, which you’ll need to register an account in order to do so. I would highly recommend doing so if you still haven’t, since they’ve got tons of datasets available on the website which you can practise on.
The next thing I’ll do is to set up my R working directory in this style, and ensure that the dataset is saved in the datasets subfolder. I’ll use the {here} workflow for this example, which is generally good practice as here::here implicitly sets the path root to the path to the top-level of they current project.
Let’s load our packages and explore the data using glimpse():
library(tidyverse)
library(here)
dball_data <- read_csv(here("datasets", "Dragon_Ball_Data_Set.csv"))
dball_data %>% glimpse()## Observations: 1,244
## Variables: 4
## $ Character <chr> "Goku", "Bulma", "Bear Thief", "Master Roshi", "...
## $ Power_Level <chr> "10", "1.5", "7", "30", "5", "8.5", "4", "8", "2...
## $ Saga_or_Movie <chr> "Emperor Pilaf Saga", "Emperor Pilaf Saga", "Emp...
## $ Dragon_Ball_Series <chr> "Dragon Ball", "Dragon Ball", "Dragon Ball", "Dr...…and also tail() to view the last five rows of the data, just so we get a more comprehensive picture of what some of the other observations in the data look like:
## # A tibble: 6 x 4
## Character Power_Level Saga_or_Movie Dragon_Ball_Seri~
## <chr> <chr> <chr> <chr>
## 1 Goku (base with SSJG ~ 448,000,000,000 Movie 14: Battle o~ Dragon Ball Z
## 2 Goku (MSSJ with SSJG'~ 22,400,000,000,0~ Movie 14: Battle o~ Dragon Ball Z
## 3 Goku (SSJG) 224,000,000,000,~ Movie 14: Battle o~ Dragon Ball Z
## 4 Goku 44,800,000,000 Movie 14: Battle o~ Dragon Ball Z
## 5 Beerus (full power, n~ 896,000,000,000,~ Movie 14: Battle o~ Dragon Ball Z
## 6 Whis (full power, nev~ 4,480,000,000,00~ Movie 14: Battle o~ Dragon Ball ZWho does the strongest Kamehameha? 🔥
In the Dragon Ball series, there is an energy attack called Kamehameha, which is a signature (and perhaps the most well recognised) move by the main character Goku. This move is however not unique to him, and has also been used by other characters in the series, including his son Gohan and his master Muten Roshi.

Goku and Muten Roshi - image from Giphy
As you’ll see, this dataset includes observations which detail the power level of the notable occasions when this attack was used. Our task here is get some understanding about this attack move from the data, and see if we can figure out whose kamehameha is actually the strongest out of all the characters.
Data cleaning
Here, we use regex (regular expression) string matching to filter on the Character column. The str_detect() function from the {stringr} package detects whether a pattern or expression exists in a string, and returns a logical value of either TRUE or FALSE (which is what dplyr::filter() takes in the second argument). I also used the stringr::regex() function and set the ignore_case argument to TRUE, which makes the filter case-insensitive, such that cases of ‘Kame’ and ‘kAMe’ are also picked up if they do exist.
dball_data %>%
filter(str_detect(Character, regex("kameha", ignore_case = TRUE))) -> dball_data_1
dball_data_1 %>% head()## # A tibble: 6 x 4
## Character Power_Level Saga_or_Movie Dragon_Ball_Seri~
## <chr> <chr> <chr> <chr>
## 1 Master Roshi's Max Power Kam~ 180 Emperor Pilaf Saga Dragon Ball
## 2 Goku's Kamehameha 12 Emperor Pilaf Saga Dragon Ball
## 3 Jackie Chun's Max power Kame~ 330 Tournament Saga Dragon Ball
## 4 Goku's Kamehameha 90 Red Ribbon Army S~ Dragon Ball
## 5 Goku's Kamehameha 90 Red Ribbon Army S~ Dragon Ball
## 6 Goku's Super Kamehameha 740 Piccolo Jr. Saga Dragon BallIf this filter feels convoluted, it’s for a good reason. There is a variation of cases and spellings used in this dataset, which a ‘straightforward’ filter wouldn’t have picked up. So there are two of these:
dball_data %>%
filter(str_detect(Character, "Kamehameha")) -> dball_data_1b
## Show the rows which do not appears on BOTH datasets
dball_data_1 %>%
dplyr::anti_join(dball_data_1b, by = "Character")## # A tibble: 2 x 4
## Character Power_Level Saga_or_Movie Dragon_Ball_Seri~
## <chr> <chr> <chr> <chr>
## 1 Jackie Chun's Max power Kameham~ 330 Tournament Saga Dragon Ball
## 2 Android 19 (Goku's kamehameha a~ 230,000,000 Android Saga Dragon Ball ZBefore we go any further with any analysis, we’ll also need to do something about Power_Level, as it is currently in the form of character / text, which means we can’t do any meaningful analysis until we convert it to numeric. To do this, we can start with removing the comma separators with stringr::str_remove_all(), and then run as.numeric().
In ‘real life’, you often get data saved with k and m suffixes for thousands and millions, which will require a bit more cleaning to do - so here, I’m just thankful that all I have to do is to remove some comma separators.
dball_data_1 %>%
mutate_at("Power_Level", ~str_remove_all(., ",")) %>%
mutate_at("Power_Level", ~as.numeric(.)) -> dball_data_2
dball_data_2 %>% tail()## # A tibble: 6 x 4
## Character Power_Level Saga_or_Movie Dragon_Ball_Seri~
## <chr> <dbl> <chr> <chr>
## 1 Goku's Super Kame~ 25300000000 OVA: Plan to Eradicate the ~ Dragon Ball Z
## 2 Family Kamehameha 300000000000 Movie 10: Broly- The Second~ Dragon Ball Z
## 3 Krillin's Kameham~ 8000000 Movie 11: Bio-Broly Dragon Ball Z
## 4 Goten's Kamehameha 950000000 Movie 11: Bio-Broly Dragon Ball Z
## 5 Trunk's Kamehameha 980000000 Movie 11: Bio-Broly Dragon Ball Z
## 6 Goten's Super Kam~ 3000000000 Movie 11: Bio-Broly Dragon Ball ZNow that we’ve fixed the Power_Level column, the next step is to isolate the information about the characters from the Character column. The reason why we have to do this is because, inconveniently, the column provides information for both the character and the occasion of when the kamehameha is used, which means we won’t be able to easily filter or group the dataset by the characters only.
One way to overcome this problem is to use the apostrophe (or single quote) as a delimiter to extract the characters from the column. Before I do this, I will take another manual step to remove the rows corresponding to absorbed kamehamehas, e.g. Android 19 (Goku’s kamehameha absorbed), as it refers to the character’s power level after absorbing the attack, rather than the attack itself. (Yes, some characters are able to absorb kamehameha attacks and make themselves stronger..!)
After applying the filter, I use mutate() to create a new column called Character_Single, and then str_remove_all() to remove all the characters that appear after the apostrophe:
dball_data_2 %>%
filter(!str_detect(Character, "absorbed")) %>% # Remove 2 rows unrelated to kamehameha attacks
mutate(Character_Single = str_remove_all(Character, "\\'.+")) %>% # Remove everything after apostrophe
select(Character_Single, everything()) -> dball_data_3## # A tibble: 10 x 5
## Character_Single Character Power_Level Saga_or_Movie Dragon_Ball_Ser~
## <chr> <chr> <dbl> <chr> <chr>
## 1 Master Roshi Master Roshi's~ 180 Emperor Pilaf ~ Dragon Ball
## 2 Goku Goku's Kameham~ 12 Emperor Pilaf ~ Dragon Ball
## 3 Jackie Chun Jackie Chun's ~ 330 Tournament Saga Dragon Ball
## 4 Goku Goku's Kameham~ 90 Red Ribbon Arm~ Dragon Ball
## 5 Goku Goku's Kameham~ 90 Red Ribbon Arm~ Dragon Ball
## 6 Goku Goku's Super K~ 740 Piccolo Jr. Sa~ Dragon Ball
## 7 Goku Goku's Kameham~ 950 Saiyan Saga Dragon Ball Z
## 8 Goku Goku's Kameham~ 36000 Saiyan Saga Dragon Ball Z
## 9 Goku Goku's Kameham~ 44000 Saiyan Saga Dragon Ball Z
## 10 Goku Goku's Angry K~ 180000000 Frieza Saga Dragon Ball ZNote that the apostrophe is a special character, and therefore it needs to be escaped by adding two forward slashes before it. The dot (.) matches all characters, and + tells R to match the preceding dot to match one or more times. Regex is a very useful thing to learn, and I would highly recommend just reading through the linked references below if you’ve never used regular expressions before.1
Analysis
Now that we’ve got a clean dataset, what can we find out about the Kamehamehas?

The Kamehameha - image from Giphy
My approach is start with calculating the average power levels of Kamehamehas in R, grouped by Character_Single. The resulting table tells us that on average, Goku’s Kamehameha is the most powerful, followed by Gohan:
dball_data_3 %>%
group_by(Character_Single) %>%
summarise_at(vars(Power_Level), ~mean(.)) %>%
arrange(desc(Power_Level)) -> kame_data_grouped # Sort by descending
kame_data_grouped## # A tibble: 11 x 2
## Character_Single Power_Level
## <chr> <dbl>
## 1 Goku 3.46e14
## 2 Gohan 1.82e12
## 3 Family Kamehameha 3.00e11
## 4 Super Perfect Cell 8.00e10
## 5 Perfect Cell 3.02e10
## 6 Goten 1.98e 9
## 7 Trunk 9.80e 8
## 8 Krillin 8.00e 6
## 9 Student-Teacher Kamehameha 1.70e 4
## 10 Jackie Chun 3.30e 2
## 11 Master Roshi 1.80e 2However, it’s not helpful to directly visualise this on a bar chart, as the Power Level of the strongest Kamehameha is 175,433 times greater than the median!
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.800e+02 4.008e+06 1.975e+09 3.170e+13 1.900e+11 3.465e+14A way around this is to log transform the Power_Level variable prior to visualising it, which I’ve saved the data into a new column called Power_Index. Then, we can pipe the data directly into a ggplot chain, and set a dark mode using theme():
kame_data_grouped %>%
mutate(Power_Index = log(Power_Level)) %>% # Log transform Power Levels
ggplot(aes(x = reorder(Character_Single, Power_Level),
y = Power_Index,
fill = Character_Single)) +
geom_col() +
coord_flip() +
scale_fill_brewer(palette = "Spectral") +
theme_minimal() +
geom_text(aes(y = Power_Index,
label = round(Power_Index, 1),
hjust = -.2),
colour = "#FFFFFF") +
ggtitle("Power Levels of Kamehamehas", subtitle = "By Dragon Ball characters") +
theme(plot.background = element_rect(fill = "grey20"),
text = element_text(colour = "#FFFFFF"),
panel.grid = element_blank(),
plot.title = element_text(colour="#FFFFFF", face="bold", size=20),
axis.line = element_line(colour = "#FFFFFF"),
legend.position = "none",
axis.title = element_text(colour = "#FFFFFF", size = 12),
axis.text = element_text(colour = "#FFFFFF", size = 12)) +
ylab("Power Levels (log transformed)") +
xlab(" ")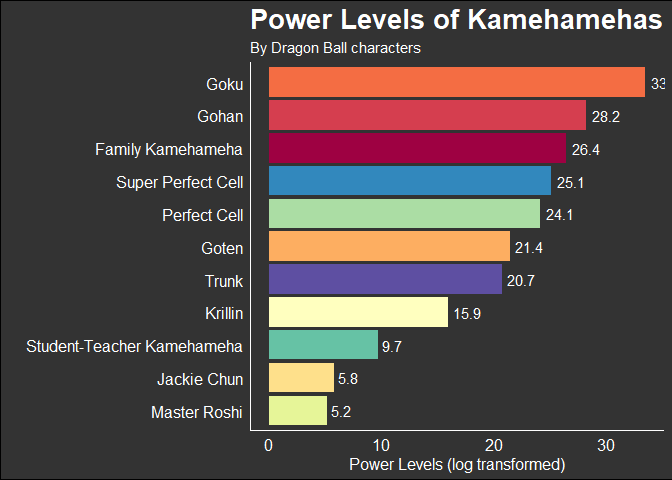
So as it turns out, the results aren’t too surprising. Goku’s Kamehameha is the strongest of all the characters on average, although it has been referenced several times in the series that his son Gohan’s latent powers are beyond Goku’s.
Also, it is perhaps unsurprising that Master Roshi’s Kamehameha is the least powerful, given a highly powered comparison set of characters. Interestingly, Roshi’s Kamehameha is stronger as ‘Jackie Chun’ than as himself.
We can also see the extent to which Goku’s Kamehameha has grown more powerful across the series. This is available in the column Saga_or_Movie. In the same approach as above, we can do this by grouping the data by Saga_or_Movie, and pipe this into a ggplot bar chart:
dball_data_3 %>%
filter(Character_Single == "Goku") %>%
mutate(Power_Index = log(Power_Level)) %>% # Log transform Power Levels
group_by(Saga_or_Movie) %>%
summarise(Power_Index = mean(Power_Index)) %>%
ggplot(aes(x = reorder(Saga_or_Movie, Power_Index),
y = Power_Index)) +
geom_col(fill = "#F85B1A") +
theme_minimal() +
geom_text(aes(y = Power_Index,
label = round(Power_Index, 1),
vjust = -.5),
colour = "#FFFFFF") +
ggtitle("Power Levels of Goku's Kamehamehas", subtitle = "By Saga/Movie") +
scale_y_continuous(limits = c(0, 40)) +
theme(plot.background = element_rect(fill = "grey20"),
text = element_text(colour = "#FFFFFF"),
panel.grid = element_blank(),
plot.title = element_text(colour="#FFFFFF", face="bold", size=20),
plot.subtitle = element_text(colour="#FFFFFF", face="bold", size=12),
axis.line = element_line(colour = "#FFFFFF"),
legend.position = "none",
axis.title = element_text(colour = "#FFFFFF", size = 10),
axis.text.y = element_text(colour = "#FFFFFF", size = 8),
axis.text.x = element_text(colour = "#FFFFFF", size = 8, angle = 45, hjust = 1)) +
ylab("Power Levels (log transformed)") +
xlab(" ")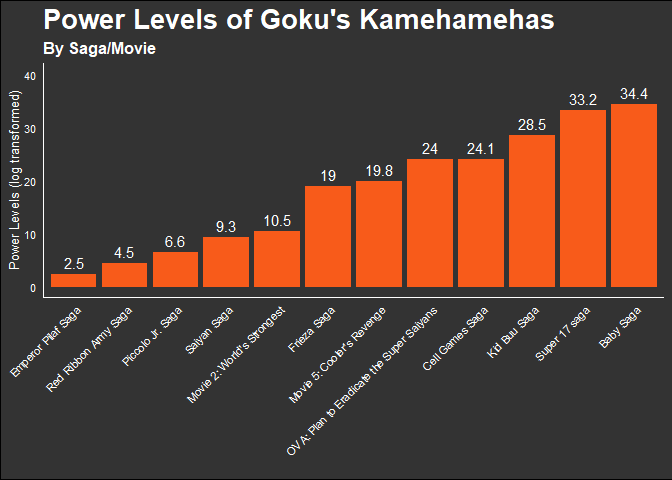
I don’t have full knowledge of the chronology of the franchise, but I do know that Emperor Pilaf Saga, Red Ribbon Army Saga, and Piccolo Jr. Saga are the earliest story arcs where Goku’s martial arts abilities are still developing. It also appears that if I’d like to witness Goku’s most powerful Kamehameha attack, I should find this in the Baby Saga!
Notes
Hope this was an interesting read for you, and that this tells you something new about R or Dragon Ball.
There is certainly more you can do with this dataset, especially once it is processed into a usable, tidy format.
If you have any related datasets that will help make this analysis more interesting, please let me know!
In the mean time, please stay safe and take care all!