
First World Problems: Very long RMarkdown documents
RMarkdown is awesome!
When I first started using RMarkdown, it felt very much like a blessing.
Not only does the format encourage reproducible analysis by enabling you to interweave code, text, images, and plots, it also allows you to knit() the document into so many different formats, including static HTML, MS Word, PowerPoint, PDF - everything done from the comfort of the RStudio IDE!
I also love the fact that whilst the outputs are highly customisable (e.g. adding your own CSS), it is also incredibly easy to produce a professional document by using an existing template (e.g. see prettydoc and rmdformats). In fact, this blog post itself is written using RMarkdown. If you haven’t tried RMarkdown yet, I’d highly recommend it - and R Markdown: The Definitive Guide is a good place to start.
But this post isn’t about selling RMarkdown. Actually, it’s about a relatively trivial inconvenience* I’ve recently experienced when using RMarkdown in work, and how I’ve found a simple solution to overcome this issue.
*hence first world problem
RMarkdown documents that are too long!

I quite often use RMarkdown to document my data exploratory analysis - e.g. when I’m coming across a completely new set of data.
The problem is simple: as I explore different cuts of the data and layer more plots, tables, and text onto my RMarkdown document, it gets unmanageably long (1,000 lines+). Although I can create more functions and source() them externally from a separate R file where possible, there is a limit to how much I can shorten the length of the Rmd file. As the file gets longer, errors become more common and debugging becomes more difficult.
However, it is not completely straightforward to split a RMarkdown document into multiple files and use source() to combine them into a single document, because source() doesn’t work on RMarkdown documents. A RMarkdown document contains more than just R code, and what you’d ideally want is to be able to combine both the code chunks and the accompanying text commentary. So I did some digging on Stack Overflow and found a solution that I was pretty happy with.1
The solution
The first step I did was to get my RMarkdown ‘contents’ into multiple files that fit into the following structure:
The “Mother” Rmd - this is the file that will take in all the content from the “child” Rmd. I would keep this file relatively short and usually just use this for loading packages and functions. This is the only Rmd file that should have a YAML header (the starting bits specifying title, author, and knit output options). There should only be one “Mother” Rmd.
“Child” Rmd(s) - these files would hold most of the analysis and be read into the “Mother” Rmd. You can have more than one of these “Child” Rmd files, and apart from the fact that these files won’t have a YAML header, they should be no different from a typical Rmd file. They’ll still have the same .Rmd file extension, and you can do section headers (e.g. h1, h2, h3…) and code chunks as normal.
My habit is then to have my working directory in the following structure, where my RMarkdown files are all saved in a Rmd sub-folder under a Scripts folder, separate from my functions. The example below shows a mother Rmd file called main_analysis_file.Rmd, and four child Rmd files named analysis-part1.Rmd, analysis-part2.Rmd, and so on:
- root project directory
- Data - where I save my raw data
- Output - where I save my analysis and plot outputs
- Scripts
- Rmds - save all Rmd scripts here
- main_analysis_file.Rmd [mother]
- analysis-part1.Rmd [child]
- analysis-part2.Rmd [child]
- analysis-part3.Rmd [child]
- analysis-part4.Rmd [child]
- Functions - save functions here
- Rmds - save all Rmd scripts here
Once I’ve organised all my analysis in the individual child Rmd files, all I need to do is to “source” these Rmd files into the “mother” file. Instead of using source(), I’ll use code chunks in the “mother” Rmd file. To make the file path referencing a bit more easier to deal with, I use here::here() to help R find the right Rmd files:2
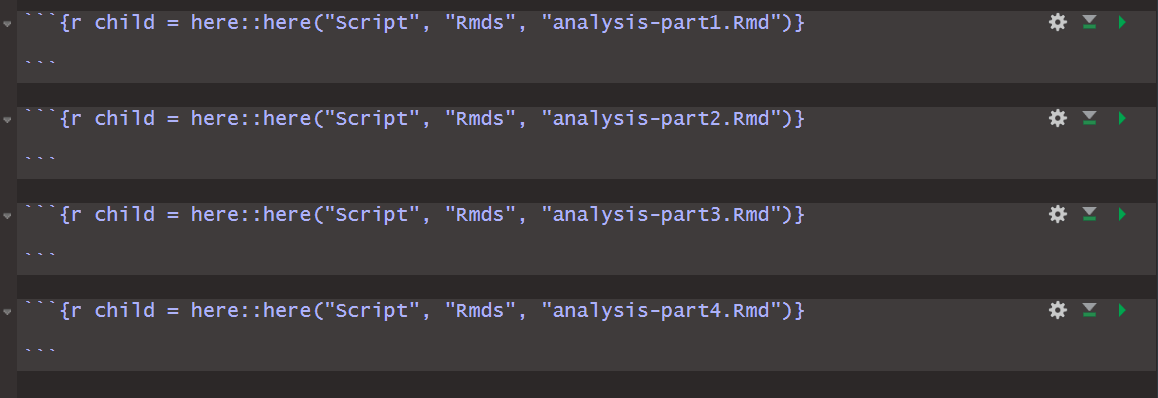
Note that you don’t need to include anything in those R code chunks within the “mother” Rmd. If everything has worked, knit-ting from the “mother” Rmd file should get you an output that draws from all the children Rmd.
Then that’s pretty much it! The outcome is that you still get outputs that contain the entire analysis, but code and documentation that is better organised and much easier to follow.
See this Stack Overflow solution that solved my problem. This solution is more suited for organising analysis projects, but bookdown may be more suitable if you’re writing a book or a thesis.↩