
RStudio Projects and Working Directories: A Beginner's Guide
Introduction 📂📂📂
This post provides a basic introduction on how to use RStudio Projects and structure your working directories - which is well worth a read if you are still using setwd() to set your directories!
Although the R working directory is quite a basic and reasonably well-covered subject, I felt that it would still be worth sharing my own approach of structuring working directories, as clearly there can be multiple sensible and valid ways of structuring a working directory. The project directory structure covered in this post is one that I use day-to-day myself, and one that I find the most appropriate for the kind of analysis work that I typically deal with, i.e. data sets loaded into memory, and saved within the working directory itself.
If you are just starting out in R, my personal advice is that using RStudio projects and structuring working directories are ‘must-knows’. Using RStudio projects eliminates so much of the early-stage hassle and confusion around reading in and exporting data. Setting up a working directory properly also helps build up good habits that are conducive to reproducible analysis. It’s one of the non-code related parts of R programming that I think is extremely helpful to know, and arguably for a learner, even a greater priority than learning how to use GitHub! 1
What is a RStudio project, and why?
When I first started using R several years ago, the textbook and mainstream approach for setting working directories was to use setwd(), which takes an absolute file path as an input then sets it as the current working directory of the R process. You then use getwd() to find out what the current working directory is, and check that your working directory is correctly set.
The problem with this approach is that since setwd() relies on an absolute file path, this makes the links break very easily, and very difficult to share your analysis with others. A simple action of moving the entire directory to a different sub-folder or to a different drive will break the links, and your script will not run. As Jenny Bryan points out, the setwd() approach makes it virtually impossible for anyone else other than the original author of the script, on his or her computer, to make the file paths work:
The chance of the
setwd()command having the desired effect – making the file paths work – for anyone besides its author is 0%. It’s also unlikely to work for the author one or two years or computers from now. The project is not self-contained and portable. To recreate and perhaps extend this plot, the lucky recipient will need to hand edit one or more paths to reflect where the project has landed on their machine. When you do this for the 73rd time in 2 days, while marking an assignment, you start to fantasize about lighting the perpetrator’s computer on fire.
(Check out this link for the original blog post)
At the beginning I was sceptical about the seemingly radical move of abandoning the setwd() orthodox entirely, but since I’ve tried out the project workflow I’ve never really thought about using absolute file paths again. So I’m totally with Jenny Bryan on this one!2
Easy file path referencing with RStudio projects
RStudio projects solve the problem of ‘fragile’ file paths by making file paths relative. The RStudio project file is a file that sits in the root directory, with the extension .Rproj. When your RStudio session is running through the project file (.Rproj), the current working directory points to the root folder where that .Rproj file is saved.
Here’s an example - let’s suppose my working directory is a folder named SurveyAnalysis1. Instead of listing out the full absolute file path, C:/Users/Martin/Documents/Analysis/SurveyAnalysis1/Data/Data1.xlsx, I can simply refer the same Excel file at the directory level when using projects, i.e. just refer to the file by Data/Data1.xlsx. The idea is that if one day I decide to move my entire SurveyAnalysis1 folder/directory to another location, or perhaps open this up on a different computer, all the file paths specified in my R scripts would still work as long as I start the session through opening the .Rproj file.
This .Rproj file can be created by going to File > New Project… in RStudio, which then becomes associated with the specified folder or directory. The mindset should then be that the directory (the whole folder and its sub-folders and contents) is stand-alone and portable, which in other words means that you shouldn’t be reading in data from or writing data to files outside the directory. Everything relating to that analysis or project should only happen within that directory, except for cases where your analysis requires interacting with an Internet source, e.g. web-scraping, calling APIs. When opening an existing project, you should open the .Rproj file first and only subsequently open any R scripts (extensions with .R) from the RStudio session, rather than going straight to the R scripts to open them. You can think of opening the .Rproj file as an ‘initialisation’ step for the RStudio session, which ensures that everything you run from this session could find the proper file paths within that directory. RStudio has a more detailed documentation on RStudio projects which is worth checking out, which has more information on .RData and .Rhistory files. Chapter 8 (Workflow: projects) of R for Data Science also gives a ‘quick start’ guide on how to use RStudio projects.
Structuring your working directory 🔨
Asides from using RStudio projects, it’s also good practice to structure your directory in a way that helps anybody else you are collaborating with - or a future version of you trying to reproduce some analysis - to navigate the analysis easily. I recommend the following as a basic ‘starter’ directory set up:
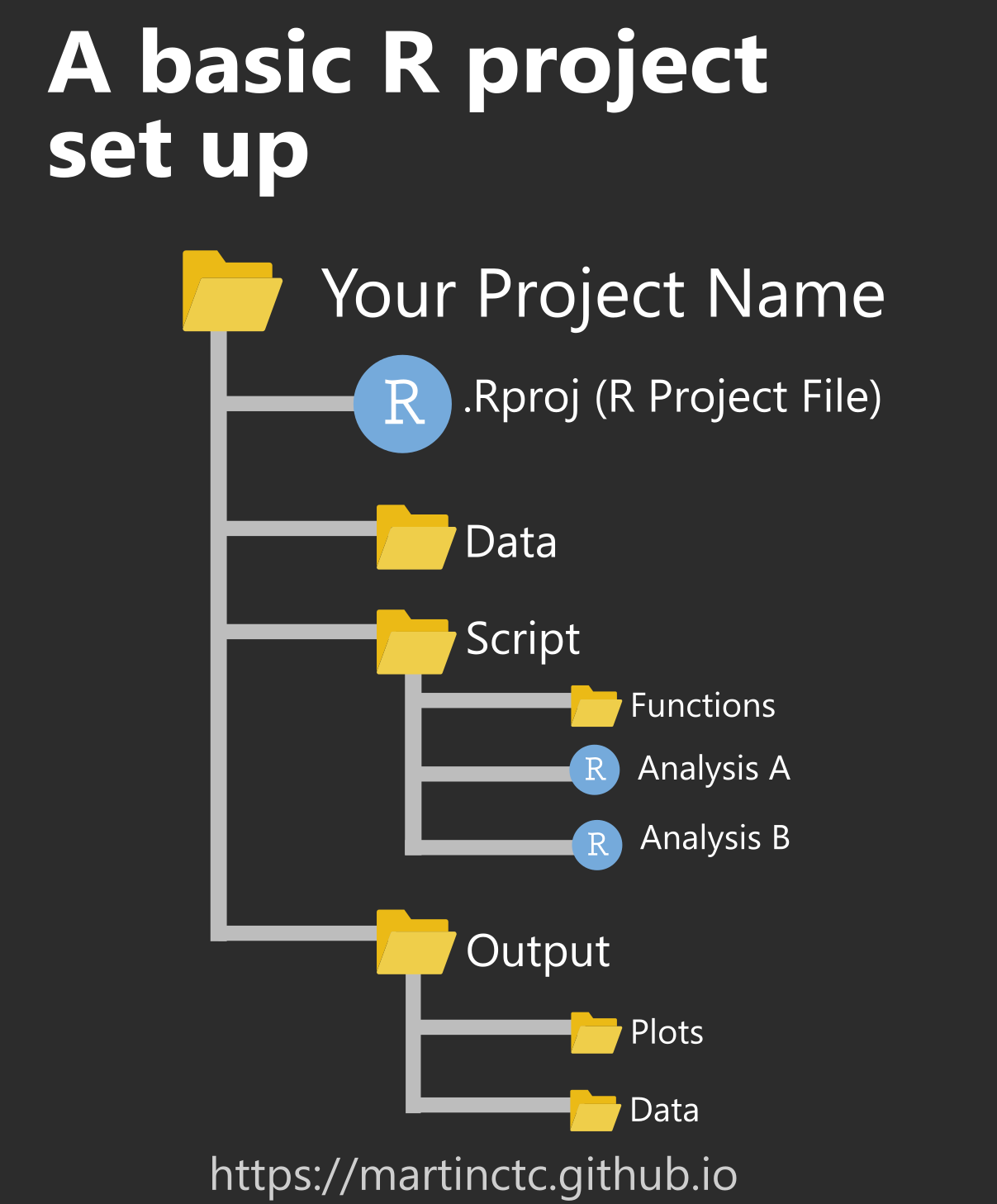
Basic Structure
In your working directory, you will have the following:
- Data - this is the subfolder where I save any files that I need to read into R in order to do my analysis or visualisation. These could be anything from SPSS (*.sav) files, Excel / CSV files, .FST or .RDS files. The key idea is that these are source data files, and at no point should R be saving over or editing these files in order to ensure reproducibility. The reasoning is that reproducible analysis isn’t really possible if the source data file keeps getting changed by the analysis (think analysis in spreadsheets). If you do need to change the source data file, create a new version and ensure that the new file name appropriately reflects that change.
- Script - this is where I save my R scripts and RMarkdown files (files with the extension .R and .Rmd).
- Analysis - All my main analysis R scripts are saved here, which I think it is for most intents and purposes fine if you have multiple scripts that perform different tasks saved here. I don’t personally have one project per distinct piece of analysis, as this could get out of hand when I may have 20+ different analysis that I’d like to perform on a single dataset. My (actually quite simple) rule-of-thumb for deciding whether to separate out an analysis is to imagine whether someone completely new to the project would be able to navigate and figure out what is going with this directory. As a side note - thoughtful and sensible file names help a lot!
- Functions - It is optional whether you have your custom functions saved in a separate sub-folder. I find this convenient personally because if I want to re-use a function that I remember I’ve written in a particular project, I can at a quick glance browse all the functions I’ve written for that project. Saving functions separately accompanies a workflow where you use
source()to read functions into the ‘main analysis script’, rather than having it together with main analysis. - RMarkdown files - RMarkdown files are a special case, as they work slightly differently to .R files in terms of file paths, i.e. they behave like mini projects of their own, where the default working directory is where the Rmd file is saved. To save RMarkdown files in this set up, it’s recommended that you use the {here} package and its workflow. Alternatively, you can run
knitr::opts_knit$set(root.dir = "../")in your setup chunk so that the working directory is set in the root directory rather than another sub-folder where the RMarkdown file is saved (less ideal than using {here}). In my other post, I briefly discussed a directory structure for combining multiple RMarkdown files into a single long RMarkdown document](https://martinctc.github.io/blog/first-world-problems-very-long-rmarkdown-documents/).
- Output - Save all your outputs here, including plots, HTML, and data exports.
- Having this Output folder helps others identify what files are outputs of the code, as opposed to source files that were used to produce the analysis.
- What you have set up as the sub-folders don’t matter too much, as long as they’re sensible. You may decide to set up the sub-folders so that they align with the analysis rather than type of file export.
- The
timed_fn()function from my package surveytoolbox (available on GitHub) helps create timestamps for file names, which I use often to ensure that I don’t lose work when I am iterating analysis.
This directory structure ‘template’ should provide a good starting point for organising projects if a project workflow is new to you. However, whilst having consistency is great, different projects will have different needs, and therefore one should always think about what is needed and what will happen when setting up the working directory structure, and adapt appropriately.
Further reading 📖
For further reading, Chris Von Csefalvay has this great article on structuring R projects, which provides a more detailed guide on what you should consider when structuring your R projects. He recommends also having a README file available for each project (saved at the root directory), which is particularly important for projects with more complexity.
As per usual, feedback, comments, and questions are all very welcome! If you like this post please do check out my other posts on https://martinctc.github.io/blog/.