
Vignette: Scraping Amazon Reviews in R
Background
One of the pet projects that I had been working on earlier in the year was to figure out an efficient way to gain an insight into what is going on in a consumer market, e.g.:
- What do people look for when they’re buying a product?
- What are the typical pain points / causes of frustration in the purchase process or in a product itself?
There are many ways to do this: usage and attitude surveys, qualitative focus groups, online bulletin-board style platform, social media mining, etc. But most of these methods take a lot of time and cost to set up, and may not be suitable if you’re trying to have a quick glimpse of what’s happening.
Amazon reviews provide a fast, accessible yet vast data resource that does both of these things, allowing you to quickly explore what’s going on at effectively zero data collection cost. In this blog post, I’ll go through some examples of how all this could be done in R with relatively few lines of code.
Note : As a data collection activity, web-scraping may have legal implications depending on your country. For the UK, as a general rule you can legally web-scrape anything out there that is in the public domain, but it is recommended that you obtain the site owner’s permission if you are reporting on the data or using the data for commercial use (See this post for a more in-depth discussion)
Getting Started 🚀
The first step is to load the tidyverse and rvest packages, as we’ll need them for building the webscraping function (e.g. parsing html) and for general data manipulation:
library(tidyverse)
library(rvest)The next step is to find out the ASIN (stands for Amazon Standard Identification Number) of the product that you want to extract reviews from. This is effectively a product ID, which can usually be found within the URL of the product link itself. ASINS are unique strings of 10 characters, where for books this would be the same as the ISBN number.
For our example, let’s use the seven volume paperback collection of George R R Martin’s A Song of Ice and Fire, which has almost 2.5K reviews on Amazon.co.uk at the time of writing. We can also specify the number of review pages to scrape, where the fixed number of reviews per page is ten. In this example, the ASIN is 0007477155, and you can find the link to the product by combining the ASIN with “https://www.amazon.co.uk/dp/”:
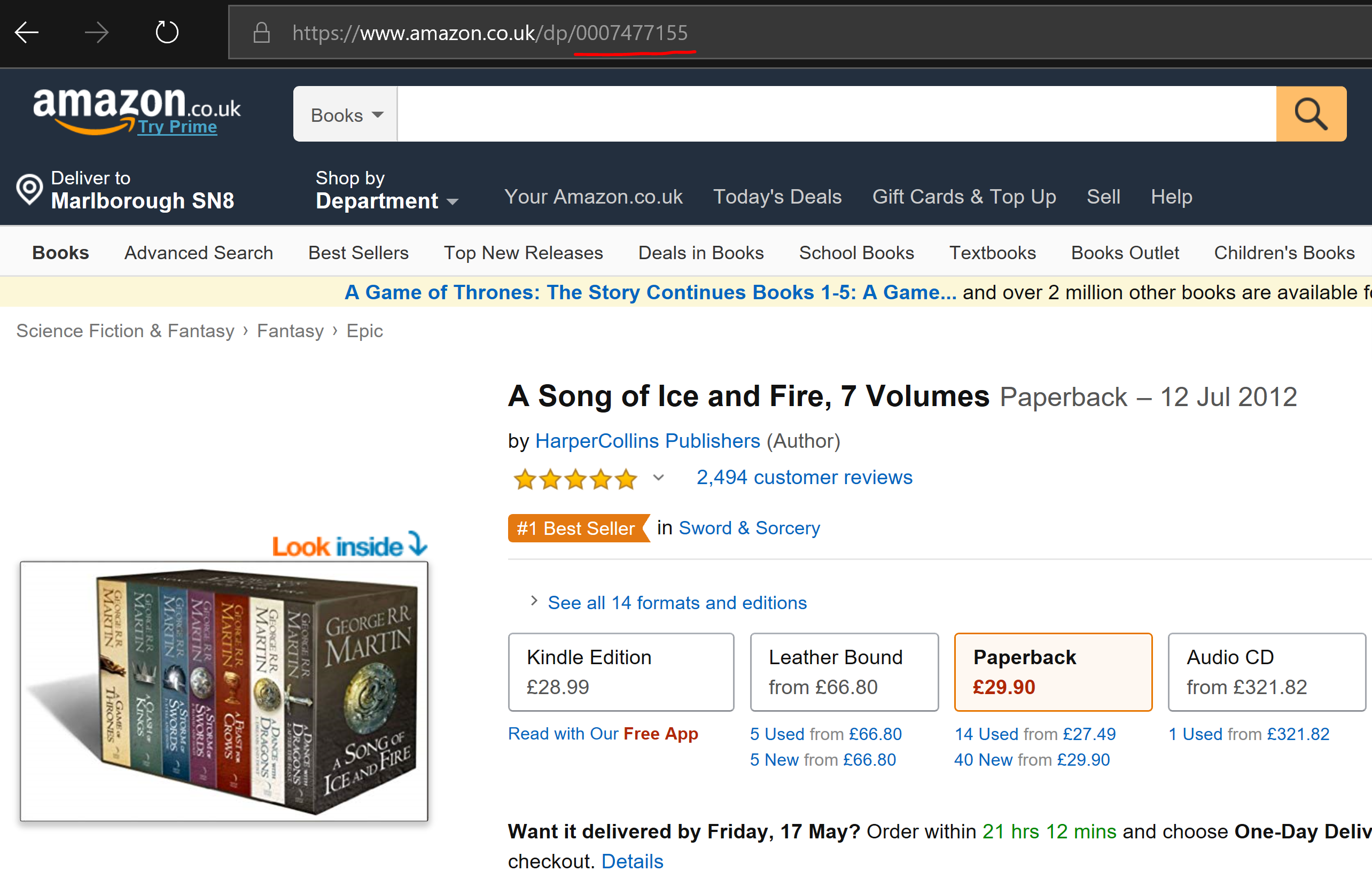
To my knowledge, the URL structure works the same way for Amazon US and Amazon UK - you can simply change the URL root to make this work for the different websites (replace ‘.co.uk’ with ‘.com’). Whether this will continue to work in the future will be dependent on whether Amazon changes the set-up of the URLs.
Writing the review scraping function
The next step is to write the main workhorse function for scraping the reviews.
In essence, what we are trying to achieve is to download the HTML content from the Amazon review page, and then use various html parsing and selector functions to organise the downloaded content into an easily manipulable format.
The read_html() function from the xml2 package reads the HTML content from a given URL, which you can assign to an object in R (so you don’t have to keep re-downloading the website) and figure out how to extract content from the object.
In this specific example of scraping Amazon reviews, our objective is to get to a table that has the following three basic columns:
- Title of the Review
- Body / Content of the Review
- Rating given for the Review
The trick is to use a combination of html_nodes() and html_text() from the rvest package to lock onto the content that you need (The rvest package recommends this really cool site for learning how to use CSS selectors).
In my function, I assign all the bits of extracted content (review title, review body text, and star rating) into individual objects, and combine them into a tidy tibble to make it easy for data analysis.
Let’s call this function scrape_amazon(), and allow it to take in the ASIN and the page number as the two arguments:
scrape_amazon <- function(ASIN, page_num){
url_reviews <- paste0("https://www.amazon.co.uk/product-reviews/",ASIN,"/?pageNumber=",page_num)
doc <- read_html(url_reviews) # Assign results to `doc`
# Review Title
doc %>%
html_nodes("[class='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold']") %>%
html_text() -> review_title
# Review Text
doc %>%
html_nodes("[class='a-size-base review-text review-text-content']") %>%
html_text() -> review_text
# Number of stars in review
doc %>%
html_nodes("[data-hook='review-star-rating']") %>%
html_text() -> review_star
# Return a tibble
tibble(review_title,
review_text,
review_star,
page = page_num) %>% return()
}You can then run this function to extract a nice, clean table of reviews:
scrape_amazon(ASIN = "0007477155", page_num = 5) %>%
head()## # A tibble: 6 x 4
## review_title review_text review_star page
## <chr> <chr> <chr> <dbl>
## 1 "Fantastic!\n " "Absolutely loved the ser~ 5.0 out of ~ 5
## 2 "Brilliant audio books\n ~ "Delivered well packaged ~ 5.0 out of ~ 5
## 3 "Epic!\n " "I don't normally read mu~ 4.0 out of ~ 5
## 4 "At 2,000 pages plus I am ~ "I have two confessions t~ 4.0 out of ~ 5
## 5 "Great value for a good co~ "I bought 'Game of Throne~ 5.0 out of ~ 5
## 6 "everybody who has read or~ "Well, everybody who has ~ 5.0 out of ~ 5Avoiding bot detection
Now that we’ve written the main web scraping function, we can add in some complexity: specifically, we can introduce systematic delays in between the HTML reads to avoid overloading web servers in a short space of time, which at the same time also helps avoid yourself being picked up as ‘suspicious webscraping behaviour’.
There are three parts to this anti-bot-detection charade:
- You can instruct R to take a three second break between each HTML read by using the
Sys.sleep()function. - You can use the modulus operator
%%to get R to take extra long breaks every x number of scrapes (to make this appear even less suspicious for a bot detector). - The third and final part to this is that you can also create a system where you scrape a sequence of pages in random order - e.g. instead of scraping pages 1 - 2 - 3, you can scrape in the order of 2 - 3 - 1.
Confession: I’m personally not 100% sure how useful or necessary all this is in avoiding bot detection (#rstatsuperstition), but I tend to include these measures anyway as they’re quite simple and fun to do…
After you’ve set this all up, you can use lapply() to loop through the page ranges:
ASIN <- "0007477155" # Specify ASIN
page_range <- 1:10 # Let's say we want to scrape pages 1 to 10
# Create a table that scrambles page numbers using `sample()`
# For randomising page reads!
match_key <- tibble(n = page_range,
key = sample(page_range,length(page_range)))
lapply(page_range, function(i){
j <- match_key[match_key$n==i,]$key
message("Getting page ",i, " of ",length(page_range), "; Actual: page ",j) # Progress bar
Sys.sleep(3) # Take a three second break
if((i %% 3) == 0){ # After every three scrapes... take another two second break
message("Taking a break...") # Prints a 'taking a break' message on your console
Sys.sleep(2) # Take an additional two second break
}
scrape_amazon(ASIN = ASIN, page_num = j) # Scrape
}) -> output_listMy R console looks like this, with the progress message: 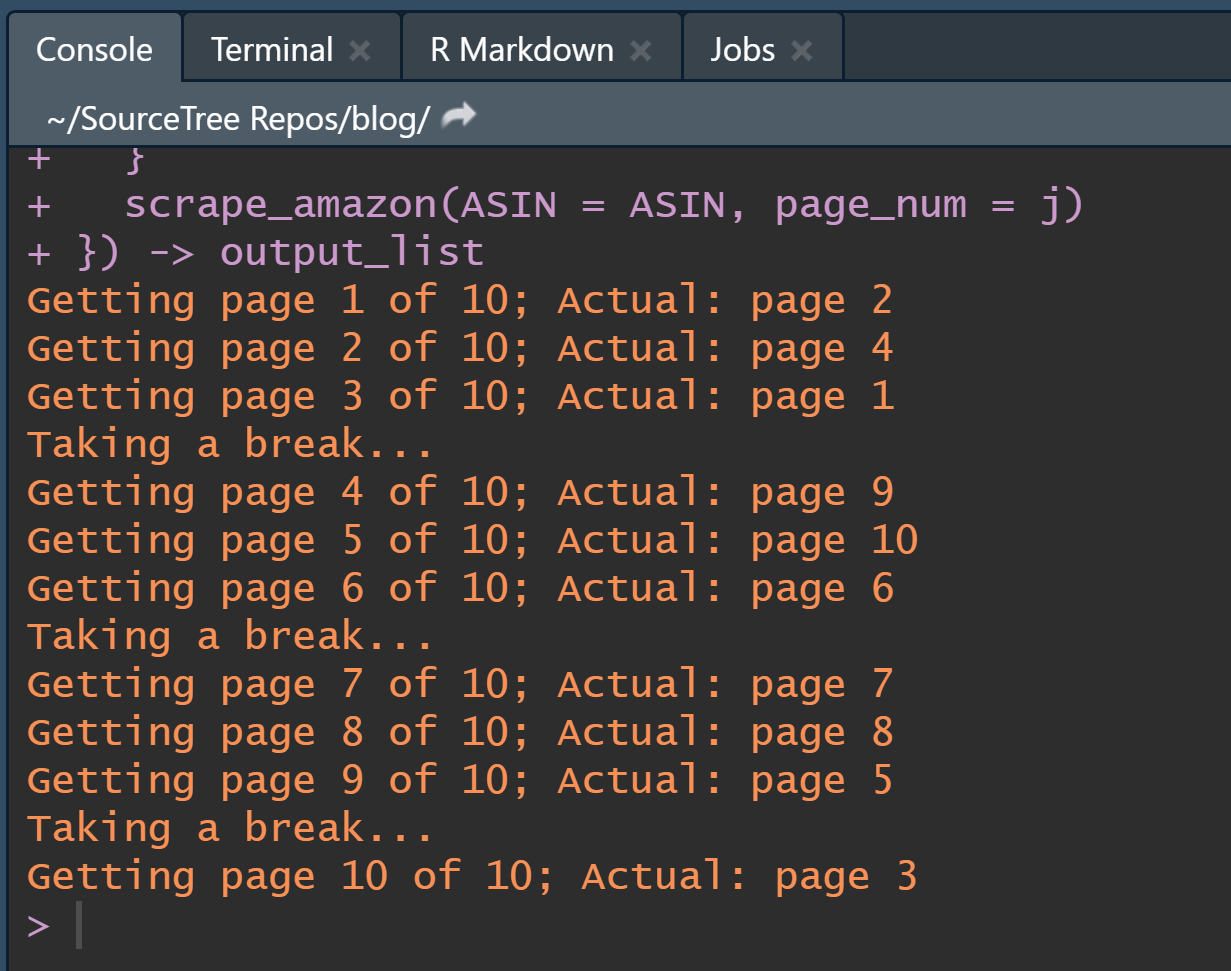 —
—
What do I do with the results?
The analytical possibilities are quite endless: word clouds, n-gram analysis, sentiment analysis, network diagrams… and definitely a topic for a separate post. To end the post, here is a quick demo of what you can easily do with ten lines of code!
library(tidytext)
library(wordcloud)
output_list %>%
bind_rows() %>%
unnest_tokens(output = "word", input = "review_text", token = "words") %>%
count(word) %>%
filter(!(word %in% c("book","books"))) %>%
anti_join(tidytext::stop_words, by = "word") -> word_tb
wordcloud::wordcloud(words = word_tb$word, freq = word_tb$n)